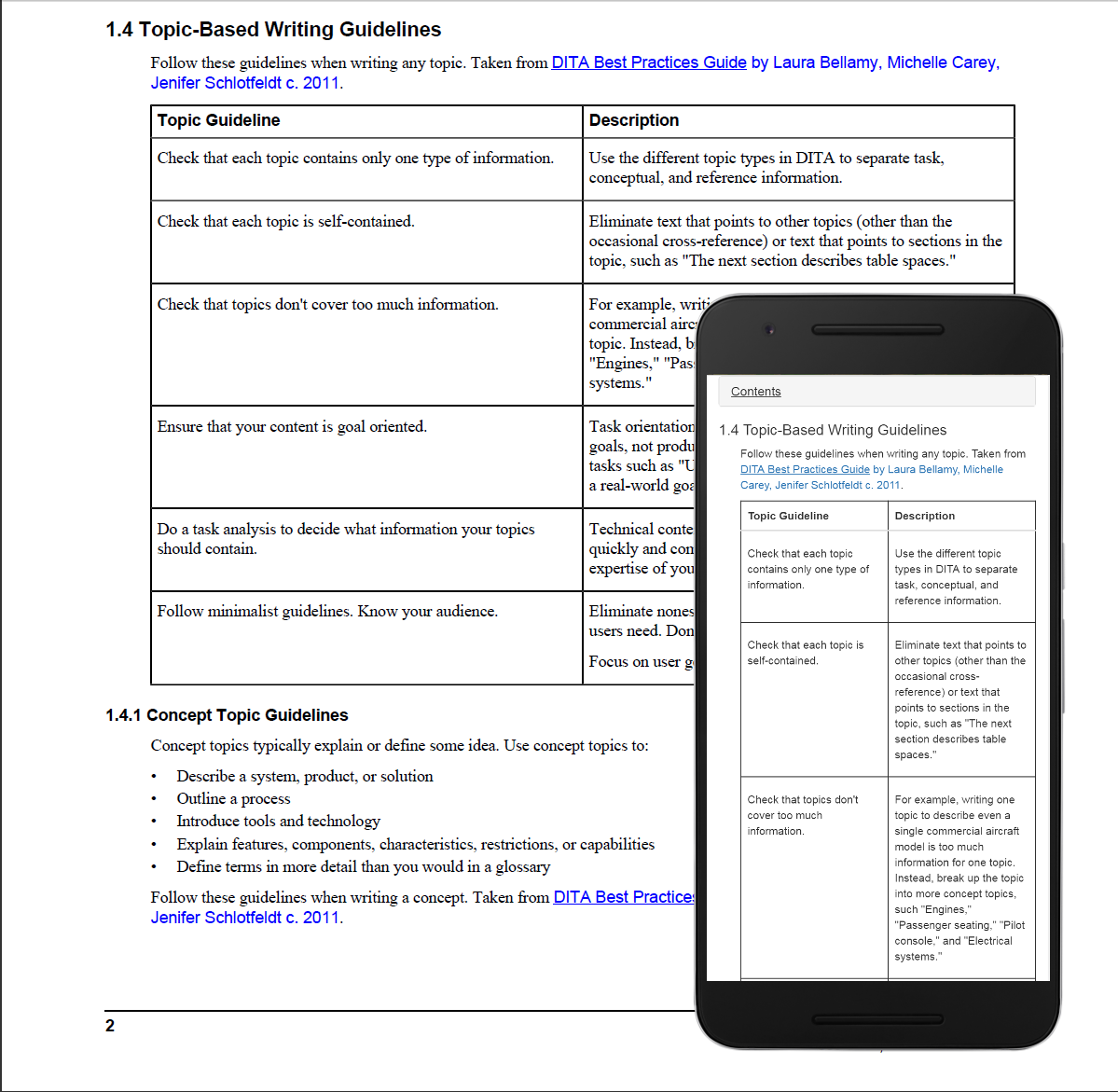
I’ve lived most of my life in California, but until recently I’d never been to any of California’s Channel Islands. This is a group of islands which extends from Catalina and San Clemente Islands in Southern California, north to the Channel Islands National Park off the coast of Santa Barbara and Ventura.
I’ve enjoyed a number of island vacations, including Sri Lanka, the Caribbean, Greece, and Polynesia. But I hadn’t really thought of an island vacation off the coast of California. After hearing friends talk about how much they enjoyed their day trip to Santa Cruz island and watching “West of the West: Tales from California’s Channel Islands”, I decided it was time to go! I scheduled a 5 day camping trip on Santa Cruz Island.
A good place to stay is Scorpion Ranch Campground, which is one of the few places on the island with easy access to drinking water. Reservations are made through Channel Islands National Park. I also arranged to have access to a kayak, which was easily done through Channel Islands Kayak Center. They also offered kayak tours, so I signed up for their “Island Cave Tour,” since the island is famous for its sea caves. I took my own wet-suit, fins, and goggles, to do a little swimming on my own.
To learn more about the Channel Islands, I started my trip with a visit to the Santa Barbara Museum of Natural History. It’s in a very nice wooded setting near the Old Mission. They have information on local flora and fauna and a very interesting exhibit on Chumash life. Through radio-carbon dating they have shown that the Chumash lived on Santa Rosa Island as long as 13,000 years ago and on San Miguel Island as long as 11,000 years ago.

I then continued on to Ventura. Getting an early start meant being all packed and ready to go the night before and staying close to the Ventura Harbor. There’s no electricity or cell phone reception at the campsite, or anywhere on the island, as far as I could tell. So I also took a couple of books and a head-lamp for the evenings. One of the books, Island of the Blue Dolphins, is based on the true story of the last surviving member of the people who lived on San Nicolas Island. The main character lived there alone for 18 years during the 19th century. I was happy to find it is still a great read.
Transportation to the islands is arranged through Island Packers, which provides regular service to Scorpion Bay on Santa Cruz Island. The boats are catamarans that ride on the surface of the water and are fast.

The ride to the island takes over an hour. Most of the passengers are day visitors and overnight school group campers. The highlight of the trip was watching as dolphins surfed in the wake of the boat. If it’s windy, the boat does its own surfing over the waves. We made brief stops, usually to let pods of dolphins pass. One of those brief stops was to pick up a Mylar balloon floating in the water; the crew made it a teaching moment to tell us about the hazards of pollution to ocean life. Turtles see the balloons as jellyfish, which are a source of food to them.
Also on view are the numerous off-shore oil derricks which still operate. There’s always been oil seeping from the ocean floor. The Chumash used it to seal their boats. But in 1969 there was a major oil spill due to a blow-out on one of the rigs. That event currently ranks as the third largest oil spill in U.S. waters, and marks a significant milestone in the modern environmental movement.
Scorpion Anchorage is the nearer of the two landing locations on the island. It had been a sheep ranch before becoming part of the National Park system.

The day we arrived it was foggy, but comfortable. And it stayed that way for a good part of the time I was there. The photo shows our approach; there’s a small pier visible just right of center in the photo. At the end of the pier is a ladder to the pier walkway.
Once we were docked, the camping gear was unloaded first, handed up the ladder by passengers and crew. I carried up my wet-suit, goggles, and fins. While we took care of that, the crew unloaded the kayaks and paddled them to shore.
It was springtime and the flowers were a treat. I wasn’t quite sure what was native or endemic, but there were knowledgeable people I could ask. Volunteers were working to eliminate invasive species such as black mustard and star-thistle.

Once threatened, but now making a comeback is the Island fox. They had co-existed with Bald eagles, which feed mostly on fish. But when the Bald eagle was eliminated in the mid-1950s, the Golden eagle moved in, and they fed on the foxes. A conservation effort in the early 2000s moved the Golden eagles back to the mainland and re-introduced the Bald eagle, which are territorial and keep out the Golden eagle. As you can see, the Island fox is not afraid of humans.

Prior to becoming part of the National Park Service, Scorpion Ranch was a sheep ranch. The buildings became the visitor center. This is a view from Cavern Point trail.

The next day I checked out Smugglers Road. You can take this for a 7.5 mile round trip hike from the campground to Smugglers Cove. It was used for smuggling by sea otter traders and others almost 200 years ago. It was also used by rum runners during Prohibition. The following photo is a view from Smugglers Road, almost directly across from where the previous photo was taken. (Cavern Point trail is visible in the upper left corner of the photo.) It shows the pier where we landed. The visitor center is just out of view to the left.

About two miles into the hike you can see the remains of an exploratory well drilled by Atlantic Richfield in 1966. They found water, not oil.

I also spent a couple of days on the water, exploring the coastline by kayak and doing a bit of swimming. There are some nice shallow caves to enter, seals to watch, and tunnels to ride through. This photo shows the volcanic rock that makes up a good part of the island.

Early morning is the best time for kayaking, as there’s only a very light wind. Later in the afternoon, the wind picks up and the water gets choppier and harder to paddle against. To stop and enjoy the view, we’d grab onto kelp or just paddle in place. Although this area is protected, swells do move through.
One thing I learned about kayaking: adjust the seat back so you sit in a more upright position; I’d been sliding down in the seat which made paddling difficult. And be sure to take plenty of fresh water. It’s easy to get dehydrated, even in overcast weather. Drinking water can reduce motion sickness.
It’s a good idea to have company, especially if you’re planning on going into the caves. I haven’t kayaked a lot, and never into caves, where timing is critical. Having guides allowed me to relax and have fun.

A good resource for additional information about the Channel Islands is in the National Park Service pamphlet “Channel Islands Interpretive Guide, Eastern Santa Cruz Island,” at: https://islandpackers.com/wp-content/uploads/2008/09/Santa-Cruz-Island-Interpretive-Guide-201414.pdf